随着这几年AI的迅猛发展,我们在图像和视频处理领域里见证了非常多的应用,比如Agora引擎里的视频超分辨率技术。对于音频中AI的应用,我们可能经常听说语音合成、语音识别等技术。那在实时音频通话中,AI有什么用武之地呢?本文将简单总结一下AI在实时音频中的应用,本文将不会展开细节,但在文末有部分参考文献,如有需要请自行取阅。
一、音频领域的超分-带宽扩展
在视频的超分中,我们可以根据相邻像素恢复出特定像素,达到使图像更清晰的目的。在音频中,空间特性往往反映在频域信号上,高频信息更丰富的音频人们听起来会更明亮。举个例子,我们在打传统落地电话时,往往会有一种感觉,对方说话的声音听起来很闷,这其实是因为传过来的语音信号被人为的移除掉了高频区域的信息。而带宽扩展的功能就是把被砍掉的这部分高频信号恢复出来,让语音信号听起来更明亮,更像面对面的交流。
实际上,带宽扩展技术已经有了很多年的发展历史,但传统的带宽扩展方法是根据音频信号的高低频区域之间的关系,计算出一些参数传递到接收端,接收端根据这些参数和信号的低频信息还原出高频信号。但这么做的话,传递的参数仍然会占用一部分带宽,因此有人提出了盲扩的思路,即只观察音频信号的低频区域,不依赖其他信息把高频区域恢复的来的方法。但这种思路在过去并没有取得令人满意的效果,直至近几年深度学习的兴起,这种思路才有所突破。
一般来说,我们可以通过训练得到一个模型,当输入一段信号的低频区域信息时,模型会拟合出对应的高频区域信息。我们再利用这些高频信息把高频信号还原出来,和低频信号结合,这样就完成了盲扩的过程。
下面是一个基于DNN的频带扩展模型的效果演示:
原始低频信号:
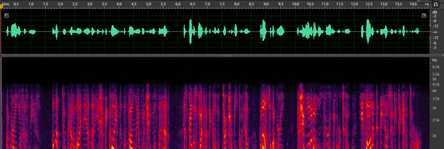
进行频带扩展后的信号:
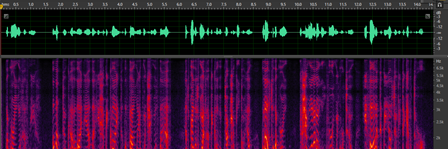
从上图可以看出,经过频带扩展后的信号增加了很多高频信息,实际的听感也会更加明亮、清晰。
二、丢包隐藏技术
众所周知,一段音频信号通过网络进行传输时,要首先被分为若干帧,然后被编码、组包、发送。在接收端会有相反的操作进行音频信号的还原。当网络状态不好或者有波动时,就会有部分包无法按时送达接收端,即发生了丢包。接收端如果不能很好的处理因为丢包带来的损伤,会严重影响恢复音频质量。在过去几十年中,音频领域的工程师设计出了很多方法去减少丢包带来的影响,常见的方法如基于波形相似的WSOLA,这种方法会通过寻找相关信号的方法,拉长前面收到的音频,也就是常说的变速不变调技术,WebRTC里现有的丢包补偿算法就是基于这种思想。还有一些内置在解码器里的基于编码参数的方法,这种方法会利用前一正常帧解码得到的信息去恢复下一帧,比如Opus就有内置的基于前一帧参数的丢包隐藏算法。但这些基于参数的方法会较频繁的补出异常声音,听起来有明显的不适。而相对来说,基于AI的模型往往通过学习大量语料,能够覆盖到更多场景,补出的声音更加自然,在丢包隐藏算法上具有较高潜力。
下面是一个基于RNN的丢包恢复模型的效果演示:
原始音频:

丢包音频:

基于AI的恢复音频:

从上图可以发现,经过丢包恢复后,丢失的信息基本已经恢复了出来,虽然难以完全恢复出原始的信息,但听觉上已经流畅了很多。
三、语音音乐分类器
为了更好的进行信号处理,引擎中有些算法往往需要被告知输入的信号是语音信号还是音频信号。分辨一段音频中哪段是语音,哪段是音乐似乎看起来不是一件困难的事情。但考虑到音频信号大多数是以20ms为一帧,只凭这20ms的信息去分辨它是语音还是音乐就没有想象中那么简单了。传统算法往往是人工设计一个模型,并基于功率谱、过零率、倒谱系数等音频特征计算出当前帧是音乐的几率,但这些算法的准确率,尤其是语音/音乐切换时的准确率并不能达到令人满意的程度。基于深度学习的分类器已被广泛应用于各个场景,在语音音乐分类器上也因其极高的准确率相对传统算法形成了显著的优势。
下图是一段混合着语音和音乐的音频的分类结果,红色的曲线是一个简单的基于GRU模型的预测结果,蓝色的是一种传统的基于HMM算法的预测结果。
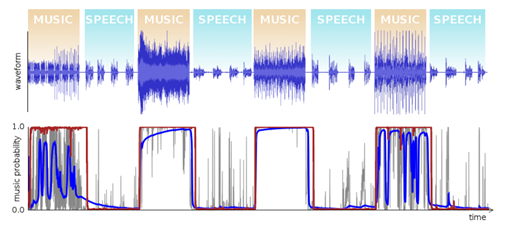
从图中可以看出,基于AI的预测结果相对该传统算法在准确性和实时性上有着明显的优势。
四、语音增强
语音增强是指当语音信号被各种各样的噪声干扰、甚至淹没后,从噪声背景中提取有用的语音信号,抑制、降低噪声干扰的技术。也就是从含噪语音中提取尽可能纯净的原始语音。这种噪声有很多种:如白噪声、电流声、开关门声、键盘打字声、啸叫声等外界噪声,也可以是由编码解码的失真带来的自身噪声。因为噪声的多样性和突发性,使得传统算法难以覆盖住较多场景。而语音增强方向一直是实时语音AI化比较热门的方向,因此涌现出了很多优秀的模型和算法。
下面是一个降噪的模型效果演示:
带噪信号:

增强后的信号:

由图可见,信号里的噪声被滤除的非常干净,而且本身有用的信息得到了有效的保护。
结语
AI的发展使得音频领域有了更多的可能性去解决之前难以处理的问题。对于实时音频而言,AI是一把全面提升质量的利刃,但实时音频所必须的低复杂度、低延时特性注定全面AI化引擎还有很长的路要走,但在不久的将来,本文总结的技术都有机会在Agora SDK里落地实现,到时,大家可以切身感受一下AI化的实时音频。
参考文献
- Speech Prediction Using An Adaptive Rcurrent Neural Network With Application To Packet Loss Concealment
Speech Prediction using an Adaptive Recurrent Neural Network with Application to Packet Loss Concealment | SigPort - Speech Bandwidth Extension Using Generative Adversial Networks
http://www.mirlab.org/conference_papers/international_conference/ICASSP%202018/pdfs/0005029.pdf - Convolution Neural Networks to Enhance Coded Speech
[1806.09411] Convolutional Neural Networks to Enhance Coded Speech