语音转文本的算法和架构,包括梅尔声谱图、MFCC、CTC Loss 和解码器。

Bruce mars 上传到 Unsplash 的照片
随着近几年 Google Home、Amazon Echo、Siri、Cortana 等自动语音识别(ASR)产品的流行,语音助手成了大众生活中的常见应用。这类应用通常是被语音唤醒并从语音中提取文本。因此,它们也被称为语音转文本算法。
前面提到的 Siri 等应用程序的功能更加完善,它们不仅能从语音中提取文本,还能分析并理解语音内容,进而作出回复或根据用户的指示采取行动。
本文主要关注使用深度学习实现语音转文本这一核心功能。和之前一样,我们不仅要理解音频深度学习是怎么工作的,还要理解这样工作的原因。
下面列出了音频深度学习系列的其他文章,欢迎大家点击阅读!这些文章探讨了深度学习领域的几个备受关注的话题,包括如何为深度学习准备音频数据、为什么深度学习模型要使用梅尔频谱图、以及如何生成和优化梅尔声谱图等。
1.前沿技术(什么是声音?声音是如何被数字化的?音频深度学习解决了我们日常生活中的哪些问题?什么是声谱图以及它为什么这么重要?)
2.为什么梅尔声谱图性能更佳(在 Python 中处理音频数据、什么是梅尔声谱图以及如何生成梅尔声谱图?)
3.数据准备和增强(通过超参数调整和数据增强来增强声谱图的功能,从而获得最佳性能)
4.音频分类(对普通声音进行分类的端到端的示例和架构、适用于多种场景的基础应用。)
5.集束搜索(语音转文本和 NLP 应用中常用的用来增强预测的算法)
语音转文本
众所周知,语言是人类工作和生活的最主要交流方式,因此语音转文本功能的应用范围非常广泛。我们使用语音转文本来功能转录客户支持或销售电话的内容,或用于语音聊天机器人,还可以记录会议以及各种讨论会的内容。
基本的音频数据由声音和噪音组成,而人类语言是比较特殊的音频数据。我在之前文章中谈到的理念,比如,如何将声音数字化、处理音频数据、为什么要将音频转换成声谱图,也都适用于人类语音,只不过人类语音更复杂,对语言进行了编码。
如果要对声音片段进行音频分类,首先要预测声音片段所属的类别(从既定类别中选择)。语音转文本的训练数据包括:
- 输入要素(X):话语片段
- 目标标签(y):话语的转录文本

自动语音识别将声波作为输入要素,把文本转录作为目标标签(图片来自作者)
此模型的目的是学习如何接收输入音频并预测说话人说的单词和句子的文本内容。
数据预处理
在音频深度学习(第四部分):声音分类,分步进行中,我详细讲解了处理音频数据的转换方法。我们可以用与之相似的方法来处理人类话语,不少 Python 库提供这样的功能,其中 librosa 是大家用的比较多的一个库。
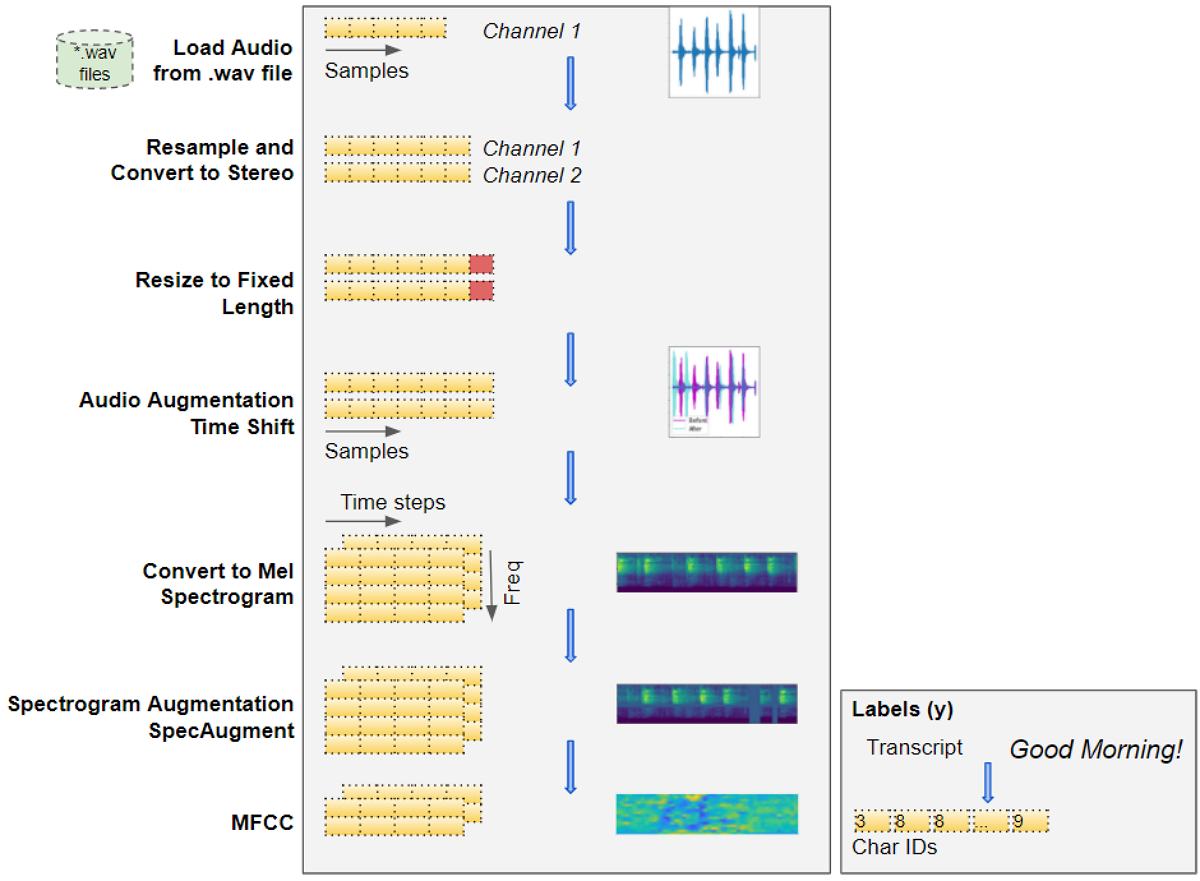
将原始音频频谱转换为声谱图,输入到深度学习模型中(图片由作者提供)
加载音频文件
-
先输入音频数据,由“.wav”、“.mp3”等格式的语音音频文件构成。
-
从文件中读取数据,加载到一个 2D Numpy 数组中。这个数组由一连串的数字组成,每个数字代表一个特定时刻的声音的强度值或振幅值。数组是由采样率决定的,例如,如果采样率是 44100 赫兹,1 秒钟时长的音频的 Numpy 数组就是 44100 个数字。
-
音频可以有一个或两个频道,即单声道或立体声。双声道音频的第二个频道会有另外一个类似的振幅数序列。换句话说,双声道的 Numpy 数组是 3D 的,深度为 2。
将采样率、频道数和持续时长转换为统一的数值
-
我们的音频数据项目可能有很多的变化,如片段的采样率不同、频道数量不同或持续时长不同,因此,每个音频项目的各方面数值都可能是不同的。
-
深度学习模型需要大小类似的输入项目,所以我们要进行数据清理来统一音频数据的大小。第一、重新取样,保证每个项目的采样率相同;第二、将所有项目转换为相同频道数;第三、所有项目必须为相同的音频时长,所以要填充较短的序列,截断较长的序列。
-
如果音频的音质很差,可能需要执行消除噪音的算法来消除背景噪音,以便听清楚语音内容。
对原始音频进行数据增强
- 可以使用数据增强技术增加输入数据的类别,帮助模型学会归纳更广泛的输入种类。我们可以将时间移位随机向左或向右移动一小段,或更改一小段音频的音调或速率。
梅尔声谱图
- 原始音频被转换为梅尔声谱图,声谱图将音频分解为一组频率,从而把音频转化为图像。
MFCC
- 处理人类语言有时需要多一个步骤,即将梅尔声谱图转换成 MFCC(梅尔频率倒谱系数)。MFCC 提取最基本的频率系数,生成一个压缩的梅尔声谱图,这些频率系数对应人类说话的频率范围。
声谱图的数据增强
- 现在可以在梅尔声谱图上使用 SpecAugment 技术进行数据增强。这涉及到频率和时间掩蔽,随机掩蔽掉声谱图中的垂直(即时间掩蔽)或水平(即频率掩蔽)的信息带。注意:我不确定这是否能应用于MFCC,也不确定结果是不是我们想要的。
现在,我们已经将原始音频文件转化为经过数据清理和增强的梅尔声谱图或 MFCC 图。
我们还需要从转录的文本中确定目标标签,这是一个由简单句子组成的普通文本,所以我们根据转录文本的字符建立了一个词汇表,并将每个字符转换成字符 ID。
这样我们就有了输入特征和目标标签,接下来可以直接把数据输入到深度学习模型中。
架构
ASR 深度学习架构有很多种,常用的两种是:
- 基于 CNN(卷积神经网络)和 RNN(循环神经网络)的架构,使用 CTC 损失算法来界定语音中的每个字符。例如:百度的深度语音模型。
- 基于 RNN 的序列到序列网络,将声谱图的每一个“切片”视为序列中的一个元素,例如:谷歌的 Listen Attend Spell(LAS)模型。
我们选取上述第一种方法,进一步了解它是如何运作的。高层次的模型由下列块组成:
- 由若干剩余 CNN 层组成的常规卷积网络,用于处理输入的声谱图并输出这些图的特征图。
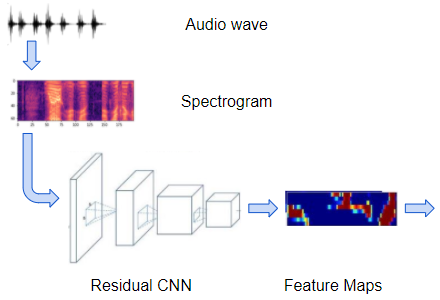
声谱图经卷积网络处理以产生特征图(图片来自作者)
- 由若干双向 LSTM 层组成的常规循环网络,将特征图处理成一系列不同的步长或“帧”,对应我们想要的输出字符的序列,话句话说,就是把作为音频的连续特征图转换成分散的。
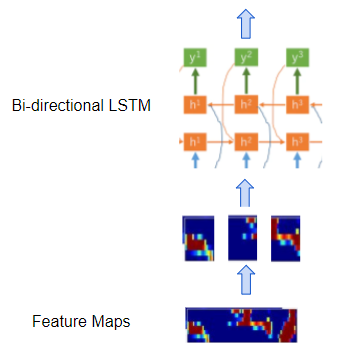
循环网络处理特征图的框架(图片来自作者)
- 一个带有 softmax 的线性层,softmax 使用 LSTM 输出为每个步长的输出产生字符概率。
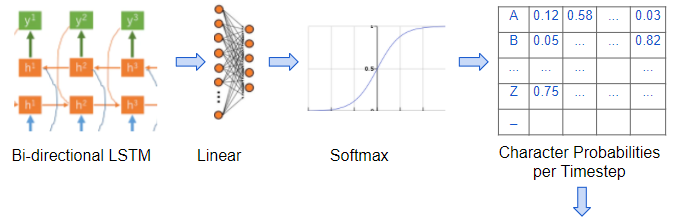
线性层为每个步长生成字符概率(图片来自作者)
- 我们还有位于卷积网络和循环网络之间的线性层,这些线性层可以帮助我们将网络的输出重塑为另一个网络的输入。
因此,我们的模型采用声谱图图像,并为该声谱图中的每个步长或 "帧 "输出字符概率。
对齐序列
稍作思考大家就会发现我们的拼图中缺少一个重要的部分。我们的最终目标是将这些步长或“帧”映射到目标转录文本中的单个字符。
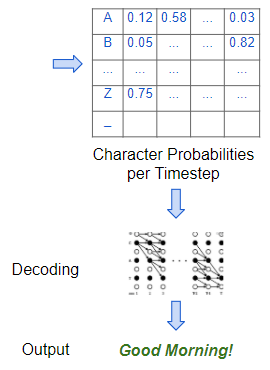
该模型对字符概率进行解码,以产生最终输出(图片来自作者)
但对于一个特定的声谱图,我们怎么知道到底应该有多少个帧?每个帧的边界在哪里?如何将音频与转录文本中的单个字符对齐?
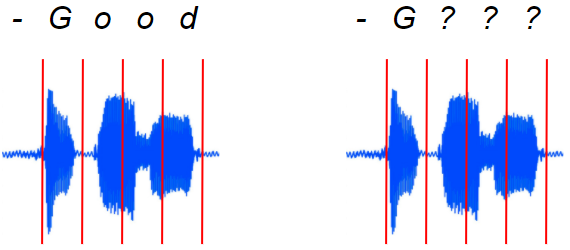
左边是我们需要的对齐,如何实现呢?(图片来自作者)
音频和声谱图没有预先分割好,所以无法提供这种信息。
-
在声谱图中,语音音频中每个字符的声音的持续时长可能是不同的。
-
字符之间可能有空隙和停顿。
-
有的字符可能合并在一起。
-
有的字符可能会重复。例如,“Apple”这个词,我们如何知道音频中“p”的发音实际上对应转录文本中的一个还是两个字符“p”?

现实生活中的口语并不是完全对齐的 (图片来自作者)
这是一个非常具有挑战性的问题,也是 ASR 很难做好的原因。这也是 ASR 与其他音频分类应用的主要不同。
我们要使用一种巧妙的算法来解决这个问题—— 连接主义时间分类(CTC)。
CTC 算法——训练和推理
如果输入是连续的,而输出是离散的,而且没有明确的元素边界来把输入映射到输出序列的元素时,可以用 CTC 来对齐输入和输出序列。
CTC 算法的特殊之处在于它能自动执行对齐,无需手动为带标签的训练数据提供对齐,节省了创建训练数据集的成本。
如上所述,模型中卷积网络输出的特征图被切成独立的帧,并输入到循环网络中。每一帧对应原始音频频谱的单个步长,但帧的数量和每一帧的持续时长都在设计模型时选择,作为超参数。对于每一帧,循环网络连接线性分类器,预测词汇表中每个字符的概率。
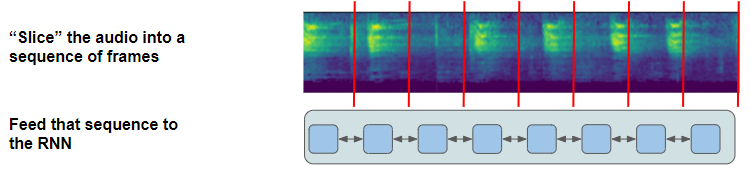
连续的音频被切成离散的帧,并输入到 RNN(图片来自作者)
CTC 算法要做的就是通过这些字符的概率推导出正确的字符序列。
为了处理上文讨论的对齐和重复字符的问题,它向词汇表引入了“空白”伪字符(用"-"表示)的概念。因此,网络输出的字符概率也包括每一帧的空白字符的概率。
需要注意的是,空白与“空格”不一样。空格是一个真实的字符,而空白意味着什么字符都没有,有点像大多数编程语言中的“null”,只用来在两个字符之间划分界限。
CTC 有两种模式:
-
CTC 损失(训练期间):它有真实的目标转录文本,通过训练网络从而最大程度地提高输出正确转录文本的概率。
-
CTC 解码(推理过程中):没有目标转录本可以参考,所以必须预测最可能的字符序列。
我们进一步探讨一下该算法的作用,从稍微简单些的 CTC 解码开始。
CTC 解码
- 使用字符概率为每一帧挑选最符合的字符,包括空白。例如:“-G-o-ood”
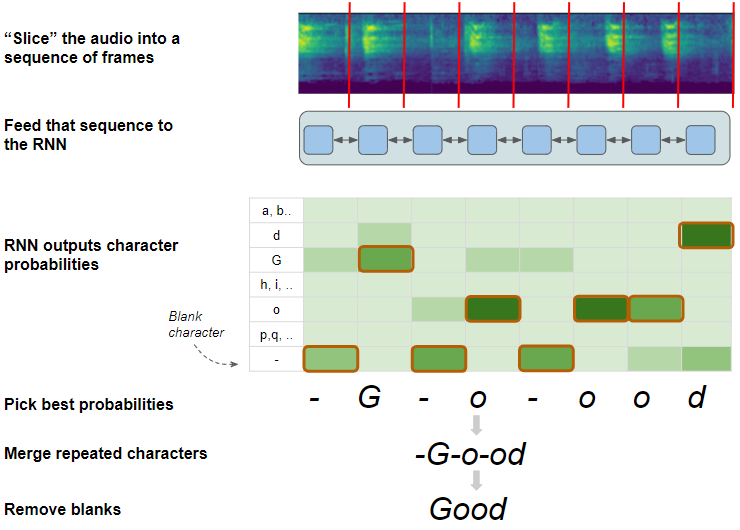
CTC 解码算法(图片来自作者)
-
合并所有重复且没有分隔符的字符。例如,可以将 "oo "合并成一个 “o”,但不能合并 “o-oo”。这样,CTC 就可以区分两个独立的“o”,进而产生由重复字符组成的单词。
-
最后,空白符完成使命之后,CTC 就删除所有的空白字符。 例如:“Good”。
CTC 损失
损失为网络预测正确序列的概率。为了预测正确序列,该算法列出了网络能预测到的所有可能的序列,并从中选择了与目标转录文本相匹配的子集。
为了从所有序列中确定子集,该算法通过以下约束条件将可能性缩小:
-
只保留目标转录文本中出现的字符的概率。 例如,只保留 “G”、“o”、“d” 和 “-”的概率。
-
使用过滤后的字符的子集,每一帧只选择与目标转录文本顺序相同的字符。 例如,尽管“G”和“o”都是有效的字符,但“Go”是有效序列,而“oG”则是无效序列。
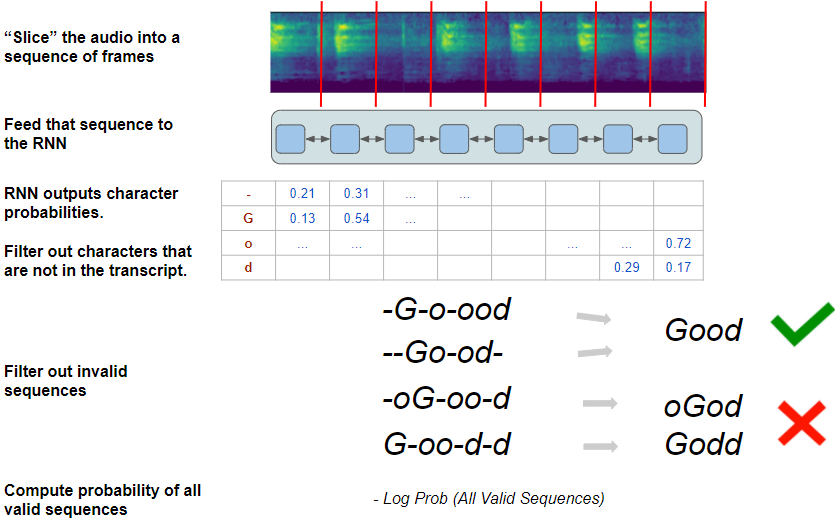
CTC 损失算法(图片来自作者)
在满足这些约束条件的情况下,算法会产生一组有效的字符序列,所有这些有效序列会产生正确的目标转录文本。 例如,使用推理过程的相同步骤,“-G-o-ood”和“-Go-od-”最终都会输出为 “Good”。
然后,使用每一帧的单个字符概率来计算产生所有有效序列的总体概率。这个网络的目标是学习如何让产生有效序列的概率最大化,减少产生无效序列的概率。
严格来说,由于神经网络将损失降到最低,CTC 损失被计算成所有有效序列的负对数。网络在训练期间通过反向传播是损失最小化,调整所有的权重以产生正确的序列。
然而,实际操作中要复杂得多。因为有各种可能的字符组合来产生序列。简单举个例子,每一帧可以有 4 个字符,那么 8 帧就有 4 ** 8(= 65536)个组合。如果转录文本有更多字符和更多帧,这个数字会以指数形式增加。所以,列出所有有效组合并计算其概率是不现实的。
CTC 的创新之处就在于它可以有效解决这个问题,单这一点就值得一篇文章,我计划接下来就写。但本文的重点是 CTC 可以实现什么,而不是研究它为什么这么运行。
衡量标准——单词错误率(WER)。
训练完网络后,我们要对它的性能进行评估。检验语音转文本的一个常用指标是单词错误率(和字符错误率)。把预测的输出和目标转录文本逐字(或逐字符)比较,计算出两者的差异数量。
差异可能是:转录文本中有这个单词但预测中没有(算作删除),转录文本中没有但预测中有(算作插入),或者是预测和转录文本的单词不一样(算作替换)。

计算转录文本和预测之间的插入、删除和替换(图片来自作者)
衡量标准的公式很好理解,即差异占总字数的百分比。

字词错误率的计算 (图片来自作者)
语言模型
我们的算法将语音音频视为对应某种语言的字符序列。但是,如果把这些字符组成单词和句子时,是否真能表达意义呢?
NLP(自然语言处理) 中的常见应用是建立语言模型,语言模型会捕捉语言是如何使用单词来构建句子、段落和文件的。它可以是一种语言(如英语或韩语)通用的模型,也可以是某个特定领域的模型,如医学或法律。
一旦有了语言模型,就可以在此基础上搭建其他应用。例如,可以用模型来预测一句话的下一个词、辨别文本的感情(例如,这是一篇积极的书评)、通过聊天机器人回答问题等。
另外,我们也可以依照语言模型引导模型产生更合理的预测,从而选择地提高 ASR 的输出质量。
集束搜索
在描述推理过程中的 CTC 解码器时,我们假设它通常在每个步长挑出一个概率最高的字符。这就是所谓的贪心搜索。
但我们还可以使用“集束搜索”来获得更好的结果。
集束搜索经常用于一般的 NLP 问题,并不专门用于 ASR,但我还是需要在这里提一下,方便大家选择。
如果你想了解更多,可以查看我的其他详细介绍 Beam Search 的文章。
总结
希望大家在读了这边文章后对解决 ASR 问题要用到的构建板块和技术有一定了解。
之前的深度学习的研究都是采用典型的方法来解决此类问题,而那些典型的方法需要了解音素等概念,还需要了解大量特定领域的数据准备和算法。
然而,本文所讲的深度学习,几乎不需要涉及任何音视频和语音知识,事半而功倍~~
原文作者 Ketan Doshi
原文链接 https://towardsdatascience.com/audio-deep-learning-made-simple-automatic-speech-recognition-asr-how-it-works-716cfce4c706